We've talked about exaggerations in "losses" due to infringement for many years. However, we've also discussed how claims of "losses" due to so-called "cybercrime" are also massively inflated. It appears that others are figuring this out as well. The NY Times has an op-ed piece from two researchers, Dinei Florencio and Cormac Herley, highlighting how all the claims of massive damages from "cybercrime" appear to be exaggerated -- often by quite a bit:
One recent estimate placed annual direct consumer losses at $114 billion worldwide. It turns out, however, that such widely circulated cybercrime estimates are generated using absurdly bad statistical methods, making them wholly unreliable.
Most cybercrime estimates are based on surveys of consumers and companies. They borrow credibility from election polls, which we have learned to trust. However, when extrapolating from a surveyed group to the overall population, there is an enormous difference between preference questions (which are used in election polls) and numerical questions (as in cybercrime surveys).
For one thing, in numeric surveys, errors are almost always upward: since the amounts of estimated losses must be positive, there’s no limit on the upside, but zero is a hard limit on the downside. As a consequence, respondent errors — or outright lies — cannot be canceled out. Even worse, errors get amplified when researchers scale between the survey group and the overall population.
This is pretty common. In the first link above, we wrote about how a single $7,500 "loss" was extrapolated into $1.5 billion in losses. The simple fact is that, while such things can make some people lose some money, the size of the problem has been massively exaggerated. As these researchers note, this kind of thing happens all the time. They point to an FTC report, where two respondents alone provided answers that effectively would have added $37 billion in total "losses" to the estimate.
This doesn't mean that the problems should be ignored, just that we should have some facts and real evidence, rather than ridiculous estimates. If the problem isn't that big, the response should be proportional to that. Unfortunately, that rarely happens. In fact, combining this with the recent ridiculous stories about the need for "cybersecurity," perhaps we can start to estimate just how much of an exaggeration in FUD the prefix "cyber-" adds to things. I'm guessing it's at least an order of magnitude. Combine bad statistical methodology with the scary new interweb thing, and you've got the makings of an all-out moral panic.
Last week, Brazil's citizens were in an uproar about the national performance rights organization (ECAD) attempting to charge a non-profit blog over $200 a month for embedding Youtube and Vimeo videos, and implicitly threatening to similarly bill other blogs. ECAD claimed that not only was this allowed by Brazil's currently-standing laws but that, despite collecting hundreds of thousands of dollars from Youtube itself every year, this new set of fees would not be a double-dip.
None other than Google Brazil itself issued a blog post stating that ECAD's existing agreement with Youtube did not allow the agency to collect fees from bloggers, pointing out the obvious to ECAD's wilfully obtuse representatives:
These sites don't host or transmit any content when they associate a YouTube video to their site, and as such, the fact of embedding videos from YouTube can't be treated as a ‘retransmission'. As these sites aren't performing any music, ECAD can't, within the law, collect any payment from these.
Having been smacked down by its main benefactor, ECAD issued a statement of its own, claiming the whole thing was just an "error" and that it had no intention of setting up tollbooths on every website with embedded video:
1- Ecad has never had the intention to curtail the freedom on the internet, known to be a space devoted to information, dissemination of music and other creative works, and propagation of ideas. The institution also lacks a copyright billing strategy geared to embedded videos. Royalties collections for webcasting have been under re-evaluation since February 29th, and the case reported in recent days took place before then. Nevertheless, it resulted from an operational error of interpretation, which represents an isolated fact in this segment. (...)
2- Two years ago, Ecad and Google signed a letter of intent that guides the relationship between both organizations. The document details thatEcad can collect copyright fees for music coming from embedded videos, as long as it gives advance notice to Google/YouTube. As Ecad did not send such a notification, it becomes clear that this is not its goal. If it were the case, it would have sent the notification the letter of intent requires. (...)
Note that ECAD has left itself a bit of an opening for pursuing these fees in the future. Supposedly it can still go after blogs but only if it informs Google/Youtube of its intention to do so. It seems the only error it feels it made was getting caught. Everything else was simply a clerical screw-up and if all ducks had been properly ordered, it would have been free to bill websites for linking to Youtube.
As it stands now, ECAD has backed completely away from this plan. But, once the furor dies down and recedes into the past, I wouldn't be surprised to see this sort of tactic deployed again, if not by ECAD, than certainly by another "aspirational" performance rights organization.
(Hat tip to Techdirt's own Glyn Moody and his amazing Twitter feed. He's asked you all very nicely to follow him and this post is an example of why you should. So, follow this link to do exactly that..)
John Steele, the former divorce lawyer who jumped into the mass copyright infringement game feet first, and who seems to keep running into problems with judges who actually understand the law, seems to be at it again. Chris sends in a report of how Steele has been sending out pre-settlement letters with totally screwed up dates, talking about a correspondence allegedly from 2007 and a lawsuit from 2006, neither of which appear to be accurate.
There are also other factually dubious statements in the letter:
The letter continues with a statement that claims that Mr. Steele's office has been unable to get in touch with the recipient.
Odd thing is, the e-mail address that is listed under the mailing address on the letter is not the e-mail address associated with the recipient's ISP. The only way Mr. Steele's firm could obtain the address would be by asking for it during a phone call. One of the five calls which Mr. Steele's firm would like to pretend never happened.
This is incredibly sloppy on the part of Steele, and with errors abounding in his letters that doesn't bode well for his lawsuits:
Personally, I believe that the implications of this letter are extremely disturbing. For one, Mr. Steele's firm appears to not bother proof-reading any of its letters. Mr. Steele is comfortable with asking for thousands of dollars from people, but he can't take 10 seconds to at least review the first sentence of his settlement letters.
There's a suggestion that some of the date errors may be due to whatever software Steele is using, but that also raises questions: if the software for creating these letters is so filled with errors, is the software he uses to track what IP addresses are sharing files also riddled with errors?
Terry Hart, who has become the go-to guy for eloquent defenses of the copyright maximalist's legal arguments lately, is at it again with a post supposedly claiming to debunk some of the posts from here on Techdirt concerning Homeland Security's seizure of domain names. Specifically, the posts that he claims to be debunking are the three posts I made highlighting the technical and legal errors in the affidavit ICE special agent Andrew Reynolds used to get a warrant to seize the domains, as well as the post which highlighted how all four songs he named to get "probable cause" for the seizure of the popular DJ blog dajaz1.com were all sent legally for the purpose of promotions.
Hart claims that if there are any errors in the affidavit they don't matter:
Are there errors in the affidavit? If so, do they even matter? The answer is no.
Hart's reasoning is that since Homeland Security only has to show "probable cause" in its affidavit, the various errors don't matter. Now, without a doubt, the standard for probable cause is different than for guilt in a trial. But that does not mean there are no standards. He quotes various Supreme Court rulings, which grant law enforcement leeway in filing the affidavits and reaching the probable cause barriers, and specifically noting that some level of mistakes are allowed. Specifically, he quotes Brinegar v. United States, where the court gives law enforcement some leeway for errors:
These long-prevailing standards seek to safeguard citizens from rash and unreasonable interferences with privacy and from unfounded charges of crime. They also seek to give fair leeway for enforcing the law in the community�s protection. Because many situations which confront officers in the course of executing their duties are more or less ambiguous, room must be allowed for some mistakes on their part. But the mistakes must be those of reasonable men, acting on facts leading sensibly to their conclusions of probability. The rule of probable cause is a practical, nontechnical conception affording the best compromise that has been found for accommodating these often opposing interests. Requiring more would unduly hamper law enforcement. To allow less would be to leave law-abiding citizens at the mercy of the officers� whim or caprice.
With all due respect to Hart, I believe his analysis falls short on a variety of different factors. First, I believe he greatly simplifies the overall ruling in Brinegar to a level that the Court almost certainly did not intend. It does allow for some mistakes (in Brinegar it was a small one). It does not allow for massive mistakes that undermine the entire probability equation that makes up probable cause. Obviously, it's expected that sometimes errors will be made. But, given the vast number of errors in this affidavit, combined with the seriousness of those errors, and the fact that (especially with dajaz1) they made up the very core of the probable cause argument, it would seem that the "balance" would shift against this affidavit having been properly executed.
Furthermore, among the Supreme Court quotes that Hart uses to support his argument is the idea that mistakes are okay because the affidavits are done "in the midst of haste of a criminal investigation." There was no urgency here, however. These sites had all been operating for years, and there was no likelihood that they would suddenly disappear. There was no reason for haste, and thus, less of an excuse for the sort of errors which may be acceptable under other circumstances. Even Hart admits that the "leeway" is about "the realities of law enforcement." The realities in this case were that there was no such urgency, and thus the mistakes are less excusable than they might be elsewhere.
More serious than this is the fact that Hart seems to ignore the specifics of what was seized and why. He notes, accurately, that seizure is much like an arrest, done prior to a trial, but (conveniently) leaves out the basis for seizures, which is supposed to be about preventing the destruction of evidence. As the Court notes in Heller v. New York, the purpose of content-based seizures is "preserving it as evidence." As we have already noted, that makes little sense in this situation, as the domain names would not and could not be "destroyed," in any meaningful manner -- and it's easy to copy the contents of the site to preserve that as evidence. Agent Reynolds explanation for why a seizure was necessary was that he was afraid that some third party might somehow get the domain name and continue the criminal copyright infringement, ignoring that an injunction could easily prevent that, and the actual likelihood of that scenario happening was close to nil.
However, the biggest flaw in Hart's argument is that he focuses solely on the issue of probable cause for warrants, and pays no attention to the key issue that we brought up: how seizing full domain names without an adversarial hearing, based on a series of legal and technical errors is almost certainly prior restraint, and a violation of the First Amendment. As was made quite clear in Fort Wayne Books, Inc. v. Indiana, when a seizure involves issues of protected speech, a higher bar is required:
Thus, while the general rule under the Fourth Amendment is that any and all contraband, instrumentalities, and evidence of crimes may be seized on probable cause (and even without a warrant in various circumstances), it is otherwise when materials presumptively protected by the First Amendment are involved... It is "[t]he risk of prior restraint, which is the underlying basis for the special Fourth Amendment protections accorded searches for and seizure of First Amendment materials" that motivates this rule.
This line of thinking goes back through a long, long, long line of cases, many of which repeat the famous line: "Any system of prior restraints of expression comes to this Court bearing a heavy presumption against its constitutional validity." In seizure cases where expressive speech is part of what is removed from circulation, the bar is higher than your average probable cause. That's why those errors are incredibly important, and the lack of any attempt to avoid First Amendment issues is glaring. Hart doesn't mention any of this, which I find surprising.
Finally, Hart closes his post (somewhat out of character for him) by suggesting our motivations for highlighting the problematic nature of the affidavit, arguing that we really don't care about the errors, and our posts are really just another way of attacking copyright law. I would suggest that Hart focus his analysis on legal issues, rather than playing amateur psychologist. My problem with the seizures is not about copyright law (though, I obviously have serious concerns about copyright law as well), but with the clear issue of a violation of the First Amendment. Separately, while Hart seems fine with it (as do the courts), I remain seriously troubled by the entire seizure process, which is widely abused, in cases where it has nothing to do with taking possession of evidence that might otherwise disappear. Playing those concerns down because there's a copyright element to this and I'm a critic of copyright law as it stands today is simply inaccurate, and seems like a cheap shot designed -- unfairly -- to attack my credibility on the situation at hand.
In statistics, there is the concept of "Type I errors" and "Type II errors," with Type I errors representing "false positives" (reject, when should be allowed) and Type II errors representing "false negatives" (allowed, when should be rejected). After reading Simon Phipps' recent excellent analysis of why DRM is "toxic to culture," it occurred to me that one of the main areas of disagreement concerning DRM is over disagreements over the types of "errors" that DRM creates. Phipps compares subways in France and Germany -- with the French subways involving a barrier which only rises if you insert a ticket. The idea here is, obviously, to prevent people from getting on the train without paying. In other words, they want to stop those who should not be in the set from riding the train. They're trying to minimize Type II errors (get on the train when they shouldn't be on the train). However, there are "costs." The barriers cost money and need to be maintained. The technology may break at times, requiring repairs and blocking legitimate ticketholders from getting on their train (a Type I error). Law enforcement is needed to monitor the barriers to watch for "gate jumpers."
In Germany, the system is much more open -- there are no barriers, and no one may ever check your ticket. However, every so often tickets do get checked (somewhat randomly), at which point you would get fined for not having the proper ticket. This minimizes a different type of error -- where someone who has paid and has a legitimate ticket has trouble getting through a gate. In other words, it's minimizing Type I errors (blocking someone from getting on the train when they should be on the train). It also lowers many of those other costs (or takes them away entirely). Of course, the "cost" to such a system is that, obviously, some number will game the system and ride without paying (a Type II error).
I think one of the problems that people have in discussing DRM is that they only look at one type of error, and never bother to compare the two. As a result of that, those who support strong DRM tend to focus only on the "error" of letting people get a "free ride," and ignore all of the collateral damage, as Phipps explains. Yet, when you compare the two, it's difficult to see how one can argue that the "free ride" problem is worse than the problem of collateral damage from limiting legitimate uses. And that is why so many people have such problems with DRM. It's not that we want a "free ride." It's that we worry about the costs associated with all of those collateral damage points.
On the Media points us to a rather extensive and amusing correction from News.com.au concerning its mistake in suggesting Captain Kirk was in charge of Captain Picard's spaceship in Star Trek:
YESTERDAY, a news.com.au article incorrectly stated that the Star Trek starship USS Enterprise-E, otherwise known as model NNC-1701-E, was the successor to Captain Kirk's original USS Enterprise.
It has since been brought to our attention that the NNC-1701-E in fact came two models after Captain Kirk retired and was under the command of Captain Jean Luc Picard.
User "Your Mum's Lunch" led the charge of those who correctly pointed out that after losing the original Enterprise to the Klingons, Captain Kirk was given the Excelsior Class Enterprise-B as a stop-gap measure until the refit of the Enterprise-A was completed.
Kirk's last ship was the Ambassador Class Enterprise-C.
Enterprise-D and Enterprise-E were in fact, the first of the Galaxy Class models and were under the command of Captain Picard.
It goes on from there, noting additional concerns about "the incorrect use of the term 'hyperspace' in describing warp drive technology." Obviously, this is a very tongue-in-cheek mocking error correction (and, if you don't believe that, just check out the photo they included with the article), poking fun at people who take Star Trek just a bit too seriously.
Furthermore, not to jump on the Star Trek nitpick wagon here, but even the correction itself is in need of correction. Any Trekker worth their salt knows that the Enterprise's designation is "NCC-1701-E" and not "NNC-1701-E."
That said, however, what struck me is how rarely you see any sort of actual correction of this nature for important stuff that publications actually do get wrong. Usually, they just make the changes to the article, and maybe append a small note at the bottom about how "changes were made," but rarely do they explain the mistakes that were made, or publish a separate article explaining the errors. And that's why the original, error-filled stories often get more attention than the corrected versions.
We've recently had our own run-in with a ridiculous threat of a libel lawsuit from the UK, in what appeared to be a clear attempt to intimidate us, rather than an action with any serious legal basis. As we mentioned in that post, thankfully, the US recently passed an important and broad anti-libel tourism law that protects US websites against overreaching foreign libel claims that go against US laws, such as Section 230 safe harbors for service providers.
So, we're always interested in hearing about other similar threats, and here's a doozy that gets more ridiculous the further you read. It starts off with just such a libel tourism attempt, but then devolves into a true comedy of threats and errors, involving misaddressed threats, ridiculous claims of confidentiality and implied threats of copyright lawsuits on publishing the letters that reveal this comedy of errors. Make sure you read through the whole thing.
It starts out with a NY-based company, GDS Publishing, who was apparently upset about the complaints about its telemarketing practices found on the website 800notes.com, specifically calling out the NY-based phone number (212 area code) used by GDS. After GDS complained to Julia Forte, who runs the site, she removed the comments that violated the site's terms of service, but left plenty of the other (non-violating, but still complaining) comments up, which GDS apparently did not appreciate. It then had a UK law firm threaten to sue her in the UK under UK libel laws. Now, it is true that GDS's parent company is based in the UK, but Julia and 800notes are in the US, and thus protected by Section 230 and the libel tourism law. And, while it doesn't even matter, given 800notes' status, this was about actions by the subsidiary, which is incorporated in New York, and all of the actions and complaints concerned that NY company (using a NY phone number).
Already, this seems like a classic case of over-aggressive lawyering, perhaps from someone unaware of the SPEECH Act, or from someone who simply hoped to intimidate an American website into compliance. However, the story gets even more ridiculous. First, the lawyer in question, one Leigh Ellis of Gillhams Solicitors LLP in the UK, apparently made a typo when copying the email address of Ms. Forte from the whois page for 800notes, resulting in him sending the initial complaint to a totally different Julia Forte (who happened to be a lawyer) based in NY, rather than the 800notes Julia Forte (who happens to live in North Carolina). Oops.
After the NY lawyer Julia Forte told Ellis of his mistake, rather than recognizing that he made a mistake, Ellis appears to have both emailed the same (wrong) Julia Forte again, and interpreted the email from the NY lawyer Julia Forte to mean that the North Carolina 800notes Julia Forte was denying her association with the site -- even though the NY lawyer Julia Forte told Ellis that he had the wrong email address. So, instead of correcting the mistake and emailing the correct Julia Forte, he sent a letter to 800notes' webhost, SoftLayer Technologies (pdf), claiming that the content on 800notes was defamatory, and saying that Forte "has informed us that she is not associated with the Website," and asking SoftLayer to confirm that Ms. Forte really is the account holder, and also demanding that SoftLayer take down the content GDS doesn't like, or face defamation charges itself.
Ah, the comedy of errors. Of course, it was the wrong Julia Forte who accurately denied being associated with the website. The correct Julia Forte has no problem standing behind her site. Thankfully, SoftLayer is well aware of the legal issues involved here, and well aware of Section 230 and the SPEECH Act that protects it, as well as Julia Forte, so it passed along the letters to Forte's lawyer, Paul Levy. If only the comedy of threats and errors ended there. But, it did not...
Levy responded in great detail to Ellis (pdf), highlighting the specific legal realities of Section 230 and the SPEECH Act, as well as detailing Ellis' own mistakes in emailing the wrong person. You should read the letter. It gets better and better as it goes along (or just skip to page 3):
Comedy of threats and errors over? Not by a long shot. After receiving Levy's letter, as well as an email correspondence in which Levy noted plans to publish Ellis's original letter to SoftLayer Technologies, Ellis' firm, Gillhams tried to warn Levy that publishing the original letter would be "unlawful" (pdf). Specifically, the law firm claims that since the original letter said "NOT FOR PUBLICATION" across the top, he had no license to publish it, and since all of their emails have a boilerplate "confidentiality notice" at the bottom, it prevents publication.
Of course, such things are simply not legally binding, leading Levy to (1) question whether or not Gillhams is charging GDS Publishing by the hour and (2) highlight how Gillhams appears to have misstated its own confidentiality clause and gotten confused over who might hold any copyright (and, thus, license-rights) to the letter in question. His response is here (pdf), though I'll restate the relevant paragraphs:
My question about whether you have been charging GDS Publishing by the hour
is relevant because, in the criticism of your conduct that I am drafting for
publication, I am trying to figure out whether your misadventures in trying to send
correspondence to Forte, and your subsequent threats directed to SoftLayer,
reflect only incompetence, or rather reflect an effort to run the meter at your
client's expense. I'd be grateful, therefore, if you would respond to my question.
Finally, I note your email referring to confidentiality notices that are contained in
your emails. Even if the emails purported to forbid publication, such notices do
not override fair use. Sad to say, however, you have misstated the fine print in
your own emails. I invite you to re-read that text. The disclaimer says that the
emails "may" contain privileged or confidential information, not that they do. I see
nothing in the emails that merits treatment as either privileged or confidential in
any event. Moreover, they instruct the recipients not to disseminate the emails if
they are NOT the intended recipients. By negative implication, these notices tell
the intended recipients that they ARE free to disseminate the emails. Your office
deliberately sent the emails to me, thus effectively giving me permission to
publish them.
Your letter also states that your "clients" are reserving their rights about the
publication of your letter and emails. However, I see no reason to believe that
your clients own the copyright in your letters. The owner would be you and/or
your firm. If you choose to try to enforce the copyright by raising a claim of
infringement, you will have to do so in your own name.
As Levy notes in his blog post on the whole situation: "I invite Ellis to bring suit here in the United States and show us that he is right. Ellis is also invited to use the comment feature to reply."
A recent lawsuit sheds even more light on just how poor quality control is at the US Patent & Trademark Office. The lawsuit specifically was over the firing of a quality assurance specialist, who's supposed to review patent examiner decisions to determine if errors were made in granting or rejecting claims. The guy was fired after it turned out that a random review showed his reviews erred 35% of the time. The guy complained that it was just a random sample rather than looking across his entire body of work, but that's not all that interesting here. What's more interesting is that apparently the "reasonable" cutoff for such QA specialists is a 25% error rate. Considering that their entire job is supposed to be double checking the work of patent examiners, you would think that getting one in four claims reviewed wrong would be ringing some pretty big alarm bells concerning the quality of any patent. No wonder so many patents are adjusted when re-examined. Even worse, the guy claims that his 35% error rate wasn't really that bad, saying that his colleagues often erred 45 to 50% of the time. What sort of QA is it that can barely QA itself?
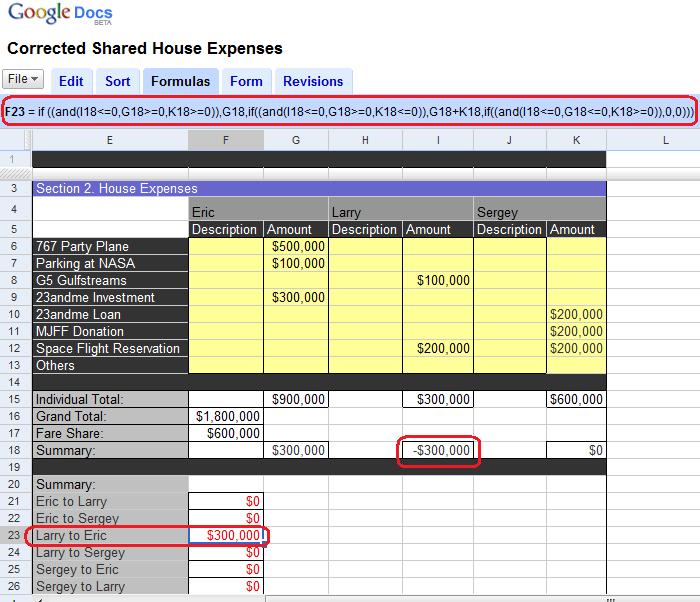
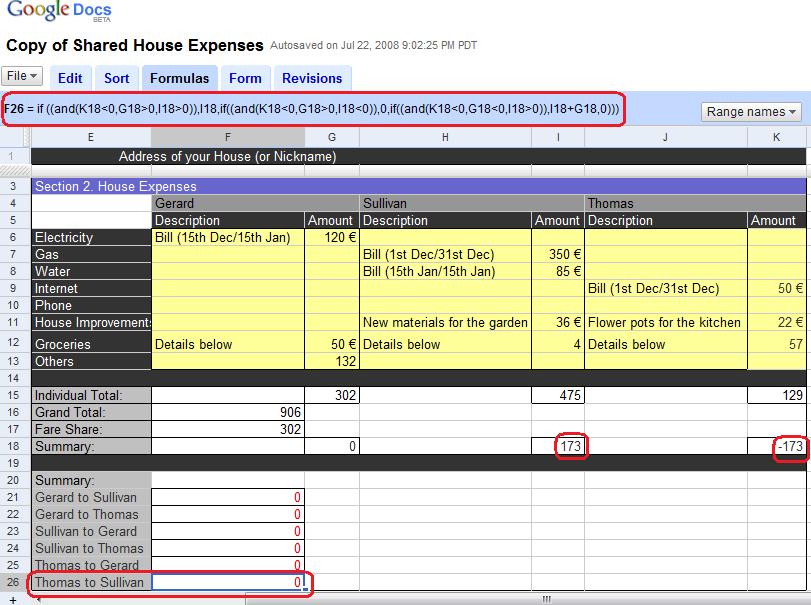
theodp writes "Recently, Google debuted its new Google Docs Template Gallery, showcasing a Shared House Expenses spreadsheet template in a pretty elaborate YouTube Video as an example of 'tools that just work.' Only problem is, the popular five-star template still doesn't work correctly. Thanks to its doesn't-handle-zero-correctly bugs, the spreadsheet fails to always divide expenses properly, allowing one roommate to get away with contributing far less than his "Fare [sic] Share." So did Google release the spreadsheet to gazillions of users without bothering to verify it worked, or did all those Googlers fail to recognize some pretty obvious mistakes?"



{kind=link}
{kind=link}
{kind=link}